Написание SEO-текста
Уровень: легко
Попробуем написать статью о больших языковых моделях при помощи приложения SEO-копирайтер. В качестве примера возьмем статью из блога компании Just AI: Большие языковые модели: что это такое и как они работают.
В качестве заголовка укажем такой же заголовок, как в оригинальной статье — Большие языковые модели: что это такое и как они работают, а в поле Ключевые слова — Определение, возможности, минусы:
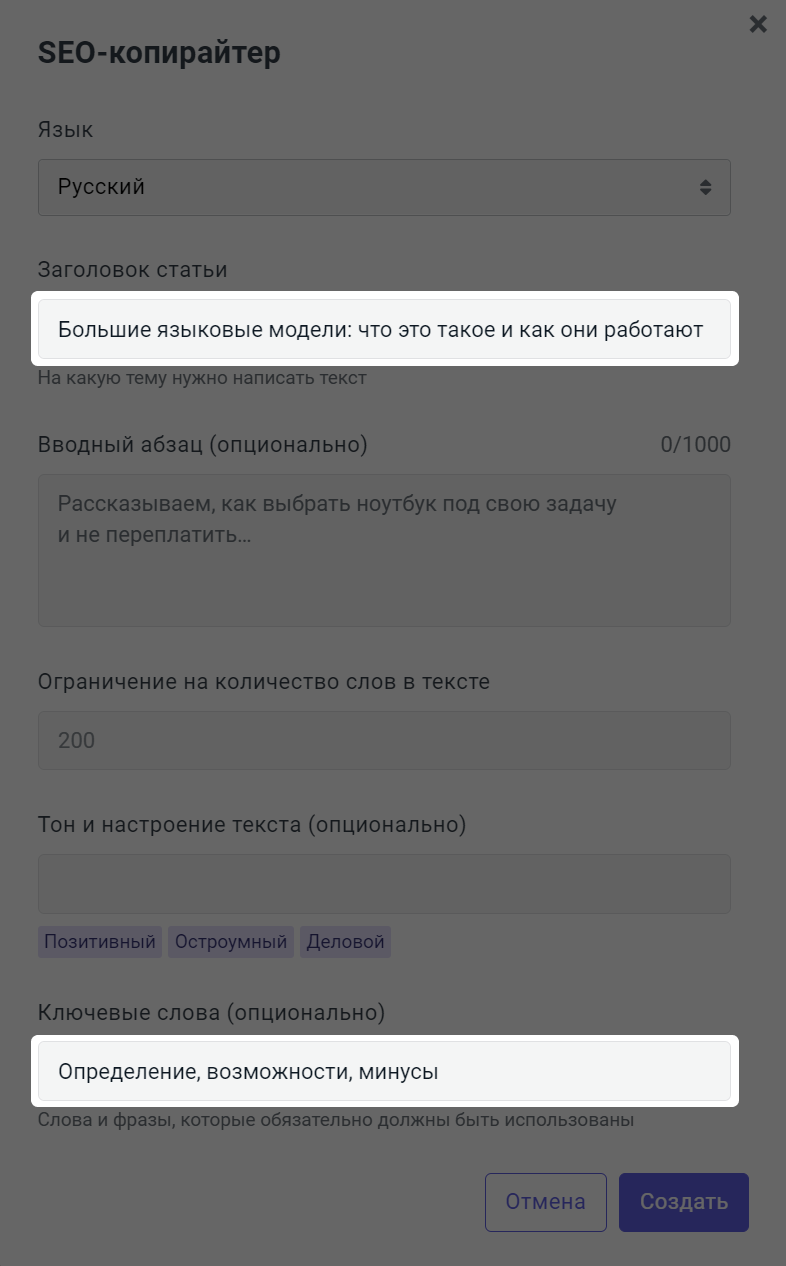
Первый вариант текста от приложения
В итоге приложение сгенерирует нам такой текст:
Большие языковые модели: что это такое и как они работают
Определение:
Большие языковые модели (Big Language Models, BLM) - это компьютерные системы, основанные на искусственном интеллекте, способные генерировать тексты на естественных языках.
Они обучаются на больших объемах текстовых данных и используют сложные алгоритмы для предсказания следующего слова или фразы в контексте.
Возможности:
Генерация текстов: БЛМ могут создавать качественные и связные тексты на различные тематики. Это может быть полезно для написания статей, блогов, описаний товаров и многого другого.
Поиск информации: БЛМ могут помочь в поиске нужной информации в больших объемах данных. Они могут обрабатывать запросы пользователей и предоставлять релевантные результаты.
Автоматический перевод: БЛМ могут использоваться для автоматического перевода текстов с одного языка на другой. Это удобно для коммуникации с людьми из разных стран.
Минусы:
Качество генерируемого текста может быть неравномерным. Иногда БЛМ могут создавать неправильные или нелогичные предложения.
Риск плагиата: из-за большого объема данных, на которых обучаются БЛМ, они могут случайно повторять уже существующие тексты.
Зависимость от доступных данных: качество работы БЛМ зависит от того, насколько хорошо и разнообразно были обучены модели.
Вывод:
Большие языковые модели - это мощный инструмент для генерации текстов и поиска информации. Они имеют свои преимущества и минусы, поэтому важно использовать их с умом и осознанностью. Компании, занимающиеся SEO оптимизацией контента, могут использовать БЛМ для создания уникального и интересного текста, который поможет улучшить ранжирование в поисковых системах.
Проведем семантический анализ текста на сторонних ресурсах.
Анализ текста
Семантический анализ текста может показать:
- Уникальность текста. Если его можно найти в другом месте, то ценность такого текста невысокая.
- Степень полезности текста. Много воды — мало полезной информации.
- Заспамленность текста. Если степень заспамленности статьи высокая, поисковые системы могут понизить ее рейтинг.
Попробуем оценить готовый текст на сторонних сервисах: Text.ru, ADVEGO, CONTENT WATCH, TurboCheck:
- Text.ru
- ADVEGO
- CONTENT WATCH
- TurboCheck
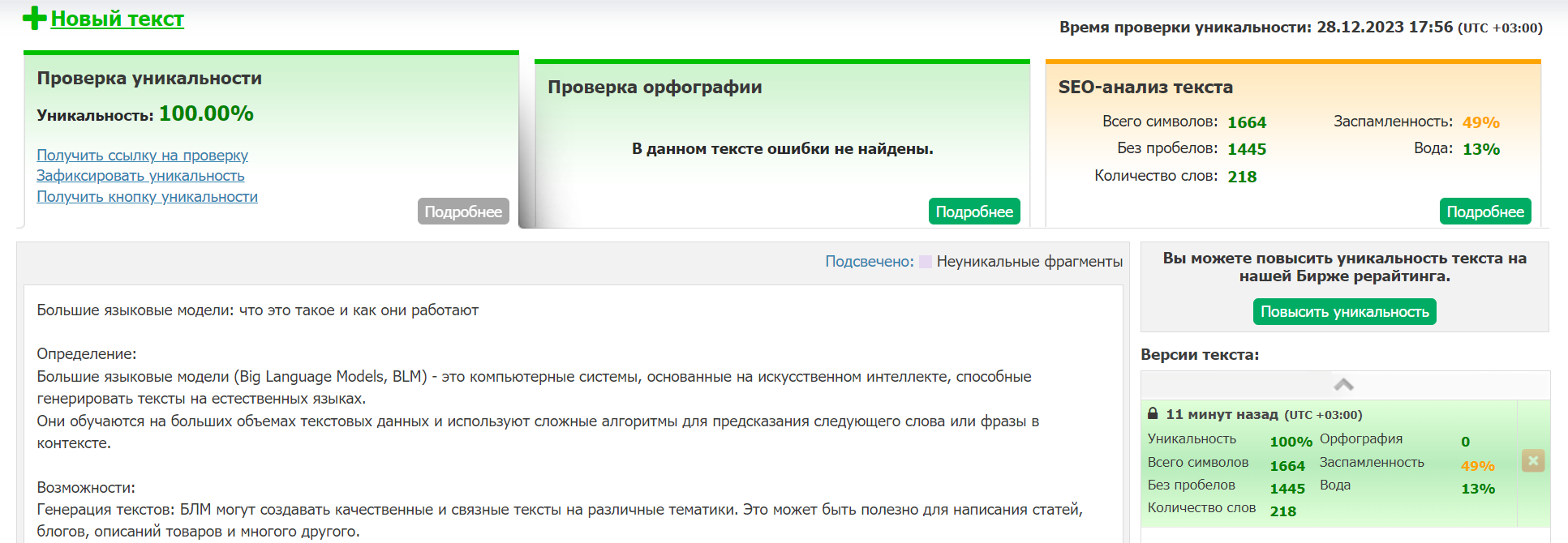
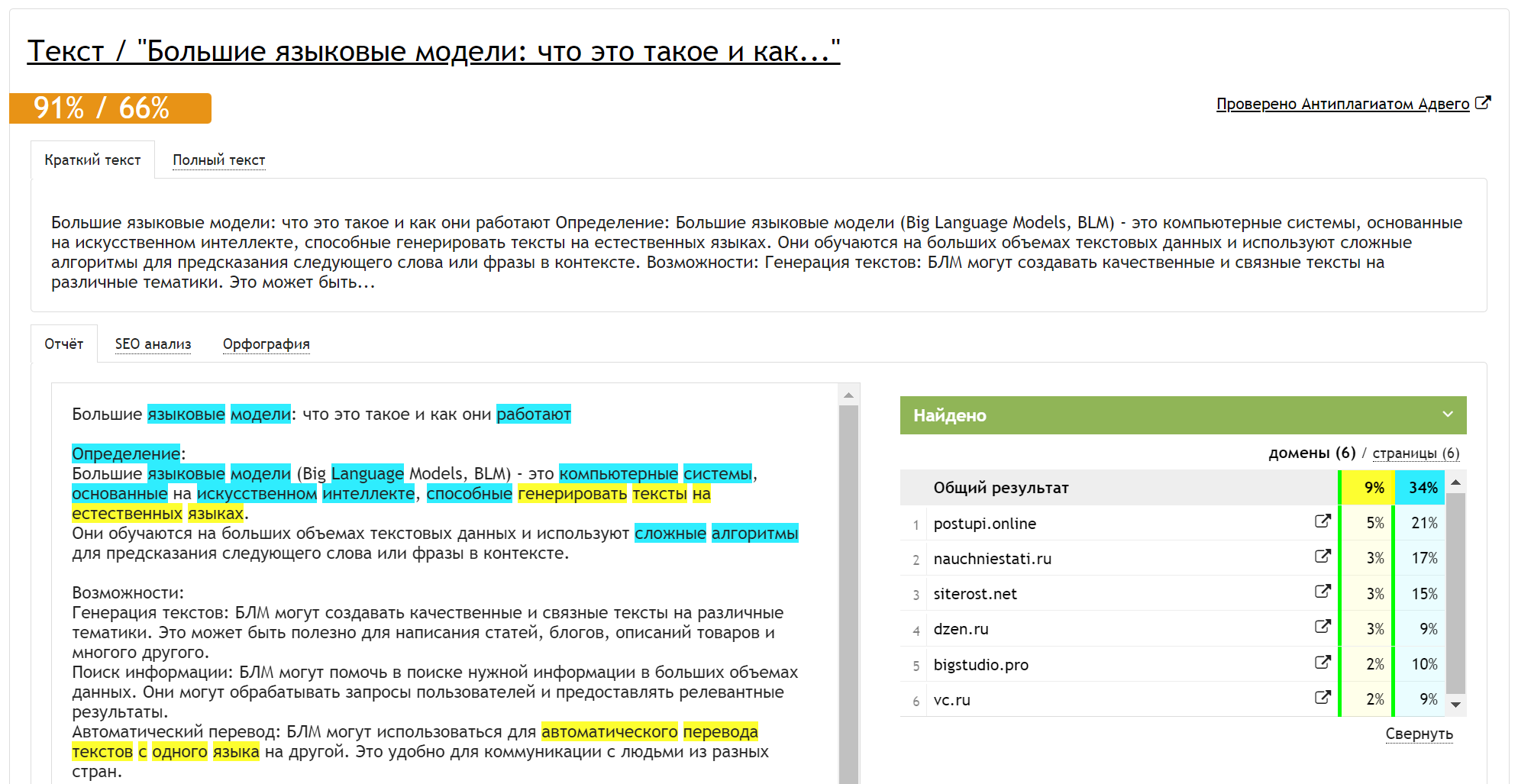
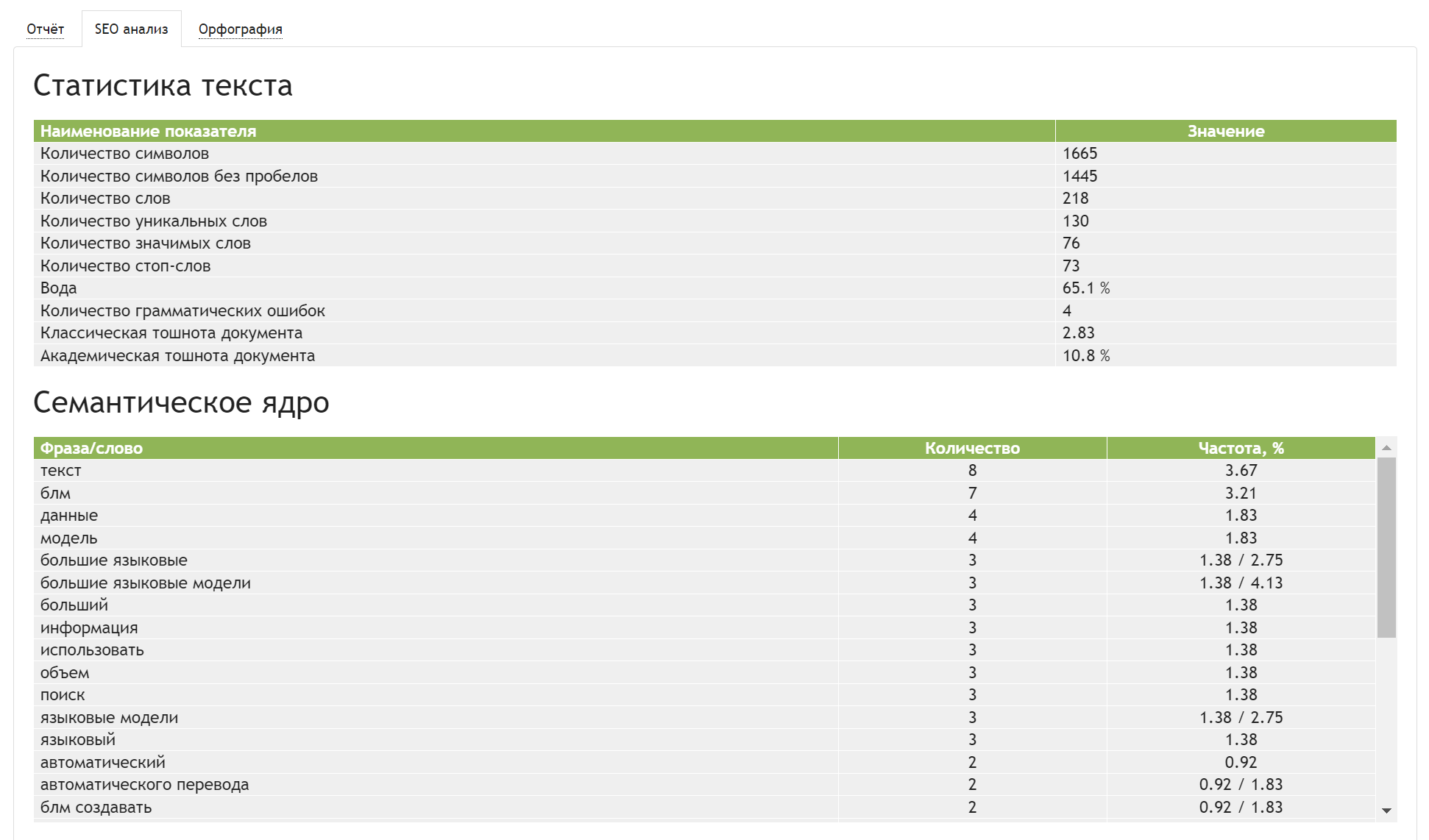
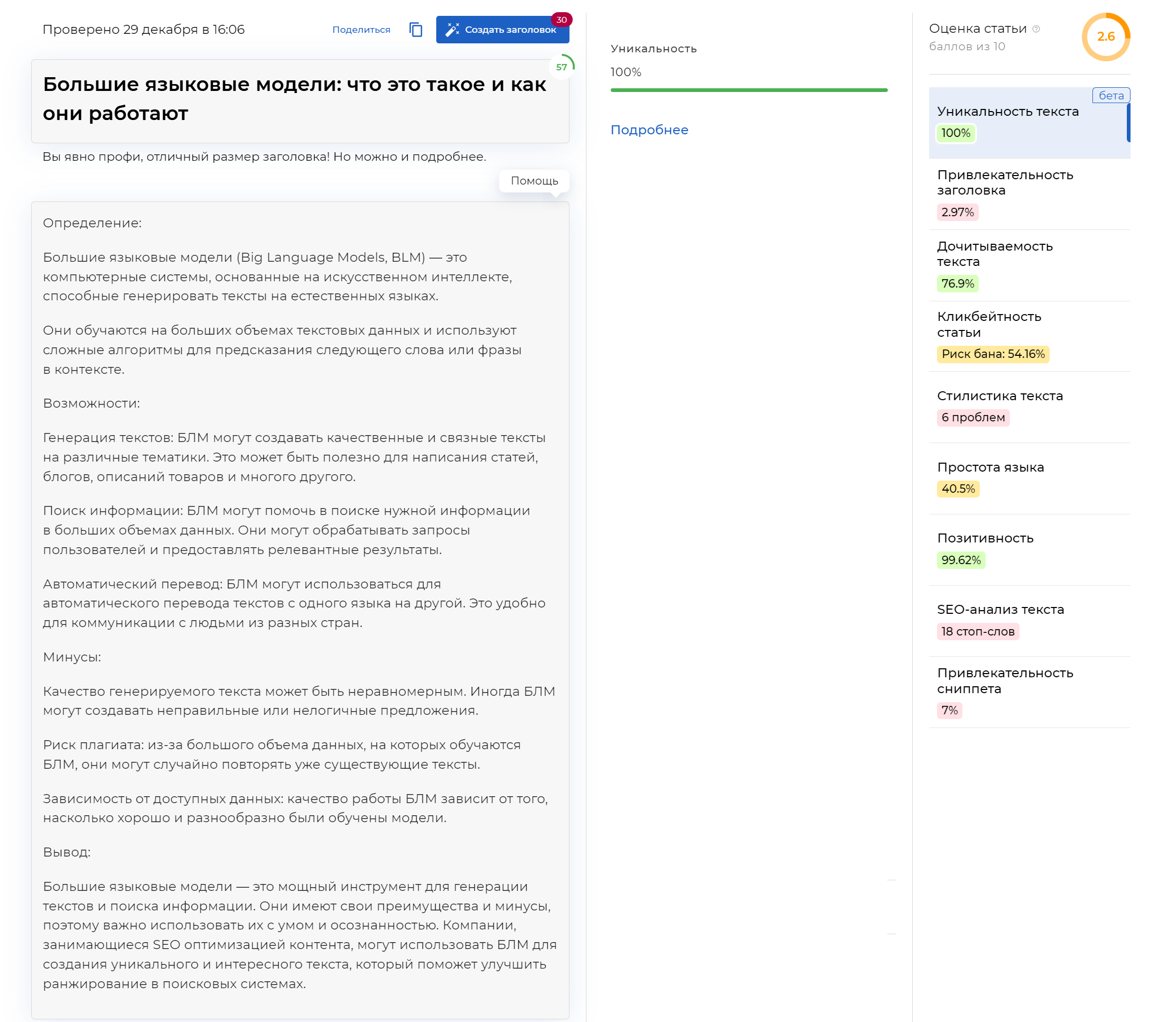
Сервис Text.ru оценил текст от приложения «SEO-копирайтер» так: уникальность — 100%, заспамленность — 49%, показатель воды — 13%:
Сервис CONTENT WATCH оценил уникальность этого текста ниже, чем предыдущие сервисы, — на 76,2%:

На сервисе TurboCheck мы оценили текст по параметрам:
- уникальность — 100%;
- привлекательность заголовка — 2,97%;
- дочитываемость текста — 76,9%;
- кликбейтность статьи — риск �бана: 54,16%;
- стилистика текста — 6 проблем;
- простота языка — 40,5% (сложный для восприятия текст);
- позитивность — 99,62%;
- SEO-анализ текста — 18 стоп-слов;
- привлекательность сниппета — 7%;
- общая оценка — 2.6 баллов из 10.
Поскольку TurboCheck предоставляет оценку по большему количеству параметров, чем другие, далее мы будем использовать его для анализа текста. При наведении на каждый показатель мы можем увидеть проблемные места в тексте. Это также поможет нам формировать более точные запросы для доработки текста.
Возможные варианты доработки текста
После анализа текста мы можем понять, что стоит доработать в тексте. Например, в тексте много воды, поэтому можно убрать некоторые предложения, которые не несут смысловой нагрузки. Также можно добавить новые предложени�я, которые расширят тему статьи, а сам текст сделать проще.
Для чистоты результатов все доработки статьи проводились при помощи приложений Jay Copilot. Не исключено, что какие-то доработки можно быстрее сделать вручную, особенно опытному копирайтеру.
Приложение «SEO-копирайтер»
При помощи приложения «SEO-копирайтер»:
-
Заменим термин Big Language Models, BLM, на корректный. На английский большие языковые модели переводятся как Large Language Models, LLM. Отправим запрос:
Большие языковые модели в английском называются Large Language Models, LLM. Исправь по всему тексту. -
Добавим больше примеров в изначальный текст, чтобы сделать его не таким голословным. Запрос:
Текст содержит оценочные прилагательные, которые не подкреплены фактами. Приведи примеры. Например, «используют сложные алгоритмы» — какие?, «в поиске нужной информации в больших объемах данных»? — большие объемы данных, это насколько большие?, «удобно для коммуникации с людьми разных стран» — почему удобно? в каких случаях? и так далее.
В итоге приложение «SEO-копирайтер» сгенерирует новый вариант текста:
Большие языковые модели: что это такое и как они работают
Определение:
- Большие языковые модели (Large Language Models, LLM) - это компьютерные системы, основанные на искусственном интеллекте, способные генерировать тексты на естественных языках.
- Они об�учаются на больших объемах текстовых данных и используют алгоритмы для предсказания следующего слова или фразы в контексте.
Возможности:
- Генерация текстов: LLM могут создавать тексты на различные тематики. Например, они могут сгенерировать статью о путешествиях, блоговый пост о кулинарии или описание товара для интернет-магазина.
- Поиск информации: LLM могут помочь в поиске нужной информации в больших объемах данных. Например, если пользователь задает вопрос о последних новостях или ищет информацию о конкретной теме, LLM могут обработать запрос и предоставить релевантные результаты. Большие объемы данных могут быть связаны с миллионами документов или записей, которые LLM анализируют для поиска ответов на запрос пользователя.
- Автоматический перевод: LLM могут использоваться для автоматического перевода текстов с одного языка на другой. Это удобно для коммуникации с людьми из разных стран и позволяет расширить географию аудитории.
Минусы:
- Качество генерируемого текста может быть неравномерным. Иногда LLM могут создавать неправильные или нелогичные предложения, особенно если им не хватает контекста или информации.
- Риск плагиата: из-за большого объема данных, на которых обучаются LLM, они могут случайно повторять уже существующие тексты. Поэтому важно проверять уникальность создаваемого контента.
- Зависимость от доступных данных: качество работы LLM зависит от того, насколько хорошо и разнообразно были обучены модели. Чем больше разнообразных данных доступно для обучения, тем лучше результаты работы модели.
Вывод:
Б�ольшие языковые модели - это мощный инструмент для генерации текстов и поиска информации. Они имеют свои преимущества и минусы. Компании, занимающиеся SEO оптимизацией контента, могут использовать LLM для создания уникального и интересного текста, который поможет улучшить ранжирование в поисковых системах. Большие объемы данных, на которых работают LLM, могут варьироваться от нескольких гигабайт до терабайтов информации, в зависимости от конкретной задачи и доступных ресурсов.
Результаты проверки этого варианта текста на сервисе TurboCheck:
- уникальность — 73,21% ( 26,79%);
- привлекательность заголовка — 2,97% (без изменений);
- дочитываемость текста — 77,18% ( 0,28%);
- кликбейтность статьи — риск бана: 54,33% ( 0,17%);
- стилистика текста — 9 проблем (� 3);
- простота языка — 38,2% ( 2,3%);
- позитивность — 99,45% ( 0,17%);
- SEO-анализ текста — 23 стоп-слова ( 5);
- привлекательность сниппета — 8% ( 1%);
- общая оценка — 2.7 баллов ( 0.1 балла).
Приложение СhatGPT
Попробуем немного скорректировать текст при помощи приложения СhatGPT. Это приложение позволяет общаться с нейросетью напрямую. При этом вы можете менять системный промт и другие настройки приложения, чтобы получить нужный результат.
Настройка приложения
При работе с приложением СhatGPT установим такие настройки:
- Модель: gpt-4o mini. Эта модель дешевле и быстрее, чем gpt-4o. С ней нам будет проще вносить исправления в будущем.
- Системный промт: You’re an SEO copywriter, a text editor. Edit the text, according to the request. In response, send the ready text in full. Указываем системный промт на английском, поскольку нейросеть ChatGPT лучше работает с английским языком.
Общение с приложением
При помощи приложения ChatGPT:
-
Поправим заголовок статьи. Для этого отправим ChatGPT запрос:
Сделай заголовок статьи более кликбейтным
Большие языковые модели: что это такое и как они работают -
Попытаемся сделать текст проще. Для начала отправим запрос:
Синоним «генерировать» — «создавать». Замени в тексте слово «генерировать и производные от него на «создавать» и производные от него:
Сам текст: …Обновленный текст на самом деле будет иметь показатель простоты ниже, чем предыдущая версия текста, но выше показатель уникальности.
Далее мы пытались сделать текст еще проще, но с каждой новой версией становилось хуже. Помимо простоты ухудшались также кликбейтность и стилистика. Поэтому мы остановились.
В итоге получился такой текст:
Удивительное открытие: разгадываем секреты больших языковых моделей и их невероятную работу
Определение:
- Большие языковые модели (Large Language Models, LLM) - это компьютерные системы, основанные на искусственном интеллекте, способные генерировать тексты на естественных языках.
- Они обучаются на больших объемах текстовых данных и используют алгоритмы для предсказания следующего слова или фразы в контексте.
Возможности:
- Генерация текстов: LLM могут создавать тексты на различные тематики. Например, они могут сгенерировать статью о путешествиях, блоговый пост о кулинарии или описание товара для интернет-магазина.
- Поиск информации: LLM могут помочь в поиске нужной информации в больших объемах данных. Например, если пользователь задает вопрос о последних новостях или ищет информацию о конкретной теме, LLM могут обработать запрос и предоставить релевантные результаты. Большие объемы данных могут быть связаны с миллионами документов или записей, которые LLM анализируют для поиска ответов на запрос пользователя.
- Автоматический перевод: LLM могут использоваться для автомати�ческого перевода текстов с одного языка на другой. Это удобно для коммуникации с людьми из разных стран и позволяет расширить географию аудитории.
Минусы:
- Качество генерируемого текста может быть неравномерным. Иногда LLM могут создавать неправильные или нелогичные предложения, особенно если им не хватает контекста или информации.
- Риск плагиата: из-за большого объема данных, на которых обучаются LLM, они могут случайно повторять уже существующие тексты. Поэтому важно проверять уникальность создаваемого контента.
- Зависимость от доступных данных: качество работы LLM зависит от того, насколько хорошо и разнообразно были обучены модели. Чем больше разнообразных данных доступно для обучения, тем лучше результаты работы модели.
Вывод:
Большие языковые модели - это мощный инструмент для генерации текстов и поиска информации. Они имеют свои преимущества и минусы. Компании, занимающиеся SEO оптимизацией контента, могут использовать LLM для создания уникального и интересного текста, который поможет улучшить ранжирование в поисковых системах. Большие объемы данных, на которых работают LLM, могут варьироваться от нескольких гигабайт до терабайтов информации, в зависимости от конкретной задачи и доступных ресурсов.
Результаты проверки этого варианта текста на сервисе TurboCheck ниже. Изменения показаны по сравнению с изначальной версией текста.
- уникальность — 95,1% ( 4,9%);
- привлекательность заголовка — 64,45% ( 61,48%);
- дочитываемость текста — 74,92% ( 1,98%);
- кликбейтность статьи — риск бана: 49,89% ( 4,27%);
- стилистика текста — 9 проблем ( 3);
- простота языка — 39,3% ( 1,2%);
- позитивность — 99,78% ( 0,16%);
- SEO-анализ текста — 23 стоп-слова ( 5);
- привлекательность сниппета — 36% ( 29%);
- общая оценка — 5.3 балла ( 2.7 балла).
Выводы
На основе рассмотренного примера мож�но сделать вывод, что вы можете использовать приложения Jay Copilot для написания черновых вариантов SEO-текстов или проработки структуры будущего текста. Также Jay Copilot может помочь, если нужно поправить какие-то мелкие недоработки в тексте. Однако для доведения текста до качественного, осмысленного все равно потребуются навыки и знания человека.